volcano做为CNCF目前唯一一款应对大规模资源批调度工具被大家熟知.
作者负责的kubernetes集群每天都有大量的任务需要运行, GPU任务、短任务、长任务等等,同时还存在多租户场景、复杂的调度策略等, 依托volcano的高度可插拔能力, 同时结合业务场景进行相应的优化,极大提高了资源使用效率,结果导向明显
在此也分享一下整个落地过程,也做为现阶段的一个工作总结, 工作之余尽量更新.
注: 业务各有不同, 作者的选型及观点可能并不适用其它人
此篇为: volcano如何应对大规模任务系列之volcano关键对象
本系列总体分为以下几块内容:
volcano如何应对大规模任务系列之volcano开篇介绍
volcano如何应对大规模任务系列之volcano关键对象
volcano如何应对大规模任务系列之volcano插件系统
volcano如何应对大规模任务系列之volcano源码解析
volcano如何应对大规模任务系列之volcano优化之道
volcano如何应对大规模任务系列之volcano生产实践
volcano如何应对大规模任务系列之volcano总结建议
本系列的所用volcano版本基于v1.7.0
架构图
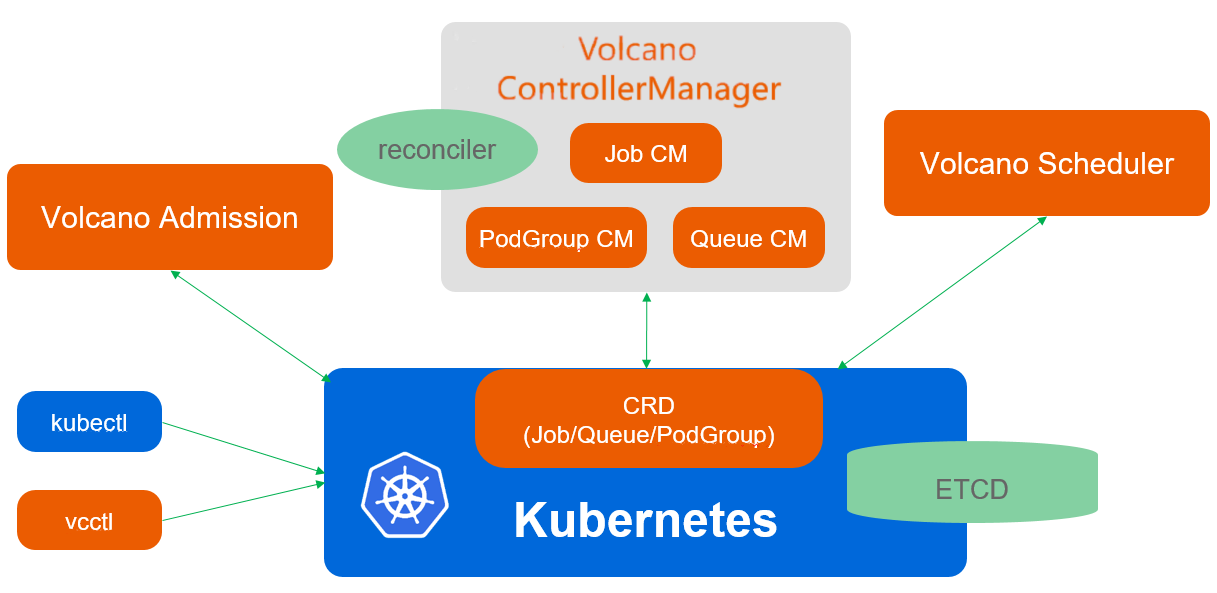
Volcano由scheduler、controllermanager、admission这三个核心组件及一个命令行工具vcctl组成:
Scheduler: Volcano scheduler通过一系列的action和plugin调度Job,并为它找到一个最适合的节点。与Kubernetes default-scheduler相比,Volcano与众不同的 地方是它支持针对Job的多种调度算法。
Controllermanager: Volcano controllermanager管理CRD资源的生命周期。它主要由Queue ControllerManager、 PodGroupControllerManager、 VCJob ControllerManager构成。
Admission: Volcano admission负责对CRD API资源进行校验。
Vcctl: Volcano vcctl是Volcano的命令行客户端工具。
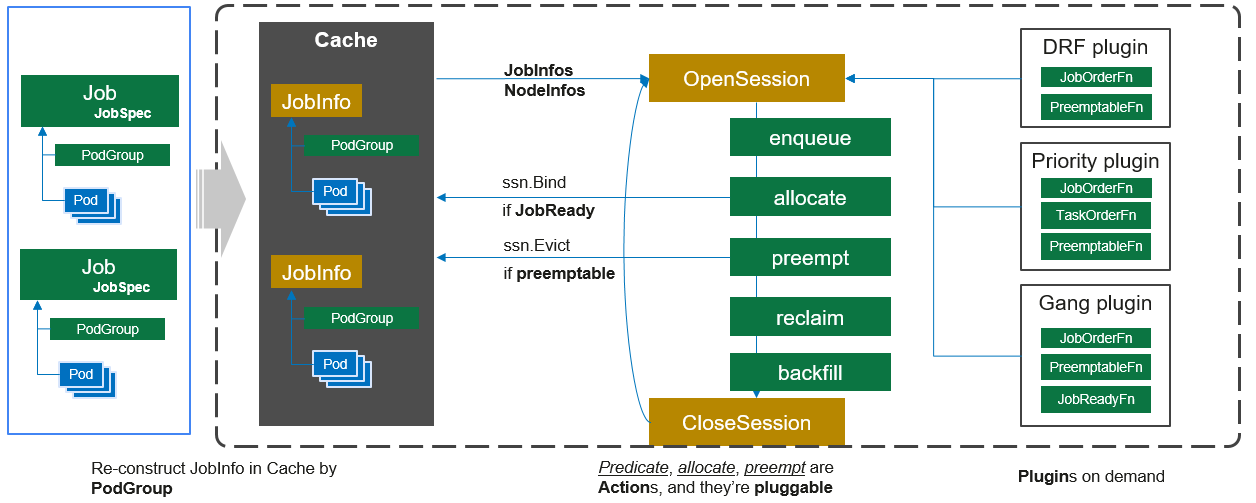
session
Session模块其实也是调度周期,默认是1s, 可配置,它的作用是承上启下。volcano在每个调度周期开始时,都会新建一个Session对象,这个Session的初始化时,会做以下操作:
- 调用Cache.Snapshot接口,将Cache中节点、任务和队列的信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。因为Cache的数据会不断变化,为了保持同个调度周期中的数据一致性,在一开始就拷贝了一份副本。
- 将配置中的各个Plugin初始化,然后调用plugin的OnSessionOpen接口。Plugin在OnSessionOpen中,会初始化自己需要的数据,并将一些回调函数注册到session中。Plugin可以向Session中注册的函数是,常用的如下:
- jobOrderFns: 决定哪个任务优先被处理
- queueOrderFns:决定哪个队列优先被处理
- taskOrderFns:决定任务中哪个容器优先被处理
- predicateFns: 判断某个节点是否满足容器的基本调度要求。比如容器中指定的节点的标签
- nodeOrderFns: 当多个节点满足容器的调度要求时,优先选择哪个节点
- preemptableFns: 决定某个容器是否可以被抢占
- reclaimableFns :决定某个容器是否可以被回收
- overusedFns: 决定某个队列使用的资源是否超过限额,是的话不再调度队列中的任务
- jobReadyFns:判断某个任务是否已经准备好,可以调用API Server的接口将任务的容器调度到节点
- jobPipelinedFns : 判断某个任务是否处于Pipelined状态,后下详解
- jobValidFns: 判断某个任务是否有效
关于plugin与各个funcion的引用关系,关注volcano如何应对大规模任务系列之volcano插件系统一节
注意Plugin不需要注册上面所有的函数,而是可以根据自己的需要,注册某几个函数。比如Predict plugin就只注册了predicateFns这个函数到Session中。
初始化成功后,volcano会依次调用不同的Action的Execute方法,并将Session对象作为参数传入。在Execute中,会调用Session的各种方法。这些方法,有些最终会调用到Cache的方法, 有些是调用Plugin注册的方法。
cache
schedulercache模块封装了对API Server的节点、容器等对象的数据同步逻辑。Kubernetes的数据保存在分布式存储etcd中,所有对数据的查询和操作都通过调用API Server的接口,而非直接操作etcd。在调度时,需要集群中的节点和容器的使用资源和状态等信息。Cache模块通过调用Kubernetes的SDK,通过watch机制监听集群中的节点、容器的状态变化,将信息同步到自己的数据结构中。
SchedulerCache会持有很多informer, 初始化的informer注册各个eventHandler,然后pod/podgroup等变动会被同步在Jobs, Nodes, Queues, PriorityClasses等几个map中。podgroup加入jobInfo,pod 加入taskInfo
action
有几个比较重要的action, 下面一一介绍
enqueue
Enqueue action筛选符合要求的作业进入待调度队列。当一个Job下的最小资源申请量不能得到满足时,即使为Job下的Pod执行调度动作,Pod也会因为gang约束没有达到而无法进行调度;只有当job的最小资源量得到满足,状态由”Pending”刷新为”Inqueue”才可以进行。一般来说Enqueue action是调度器配置必不可少的action(v1.7+版本后可disable)
在volcano中, 只有通过了enqueue后的任务(即由pending状态变成inqueue状态)才有资格进行真正资源的allocate, 因此,对enqueue action的逻辑需要理解, 源码解析一章中也会有这方面的分析
Enqueue action是调度流程中的准备阶段
allocate
Allocate action是调度流程中的正常分配步骤,用于处理在待调度Pod列表中具有资源申请量的Pod调度,是调度过程必不可少的action。这个过程包括作业的predicate(预选)和prioritize(优选)。使用predicateFn预选,过滤掉不能分配作业的node;使用NodeOrderFn打分来找到最适合的分配节点。
Allocate action遵循commit机制,当一个Pod的调度请求得到满足后,最终并不一定会为该Pod执行绑定动作,这一步骤还取决于Pod所在Job的gang约束是否得到满足。只有Pod所在Job的gang约束得到满足,Pod才可以被调度,否则,Pod不能够被调度
reclaim
volcano支持弹性的资源使用,当queue中的资源没有被使用时,可暂被其它queue占用,reclaim action则是用于回收那些超格使用了queue上限的额外资源
preempt
Preempt action是调度流程中的抢占步骤,用于处理高优先级调度问题。Preempt用于同一个Queue中job之间的抢占,或同一Job下Task之间的抢占
backfill
Backfill action是调度流程中的回填步骤,处理待调度Pod列表中没有指明资源申请量的Pod调度,在对单个Pod执行调度动作的时候,遍历所有的节点,只要节点满足了Pod的调度请求,就将Pod调度到这个节点上。
plugins
volcano中包含了很多的plugin, 主要作用是在action下实现特定的业务逻辑, 现有的大部分plugin作者都在生产环境应用过,因此有一些生产经验可谈,关注volcano如何应对大规模任务系列之volcano插件系统一节,不过,还是先把所有的plugin简单介绍一下
gang
Gang调度策略是volcano-scheduler的核心调度算法之一,它满足了调度过程中的“All or nothing”的调度需求,避免Pod的任意调度导致集群资源的浪费。具体算法是,观察Job下的Pod已调度数量是否满足了最小运行数量,当Job的最小运行数量得到满足时,为Job下的所有Pod执行调度动作,否则,不执行。
kube-scheduler本质上是个串行的调度器,而gang则可实现并行的效果
Binpack
binpack调度算法的目标是尽量把已有的节点填满(尽量不往空白节点分配)。具体实现上,binpack调度算法是给可以投递的节点打分,分数越高表示节点的资源利用率越高。binpack算法能够尽可能填满节点,将应用负载靠拢在部分节点
Binpack算法以插件的形式,注入到volcano-scheduler调度过程中,将应用在Pod优选节点的阶段。Volcano-scheduler在计算binpack算法时,会考虑Pod请求的各种资源,并根据各种资源所配置的权重做平均。每种资源在节点分值计算过程中的权重并不一样,这取决于管理员为每种资源配置的权重值。同时不同的插件在计算节点分数时,也需要分配不同的权重,scheduler也为binpack插件设置了分数权重。
工作节点上的应用拥塞程度跟binpack的设定的参数有很大关系
Priority
Priority plugin提供了job、task排序的实现,以及计算牺牲作业的函数preemptableFn,job的排序根据priorityClassName,task的排序依次根据priorityClassName、createTime、id。
DRF
DRF调度算法的全称是Dominant Resource Fairness,是基于容器组Domaint Resource的调度算法。volcano-scheduler观察每个Job请求的主导资源,并将其作为对集群资源使用的一种度量,根据Job的主导资源,计算Job的share值,在调度的过程中,具有较低share值的Job将具有更高的调度优先级。这样能够满足更多的作业,不会因为一个胖业务,饿死大批小业务。DRF调度算法能够确保在多种类型资源共存的环境下,尽可能满足分配的公平原则。
Proportion
Proportion调度算法是使用queue的概念,用来控制集群总资源的分配比例。每一个queue分配到的集群资源比例是一定的
proportion在queue中很重要,弹性的资源分配就是由proportion实现
Predicates
Predicate plugin通过pod、nodeInfo作为参数,调用predicateGPU,根据计算结果对作业进行评估预选
Task-topology
Task-topology算法是一种根据Job内task之间亲和性和反亲和性配置计算task优先级和Node优先级的算法。通过在Job内配置task之间的亲和性和反亲和性策略,并使用task-topology算法,可优先将具有亲和性配置的task调度到同一个节点上,将具有反亲和性配置的Pod调度到不同的节点上
Nodeorder
Nodeorder plugin是一种调度优选策略:通过模拟分配从各个维度为node打分,找到最适合当前作业的node。打分参数由用户来配置。参数包含了Affinity、reqResource,、LeastReqResource、MostReqResource、balanceReqResouce
跟binpack一样, nodeorder的不同参数,对节点的调度结果有很大的不同
SLA
SLA的全称是Service Level agreement。用户向volcano提交job的时候,可能会给job增加特殊的约束,例如最长等待时间(JobWaitingTime)。这些约束条件可以视为用户与volcano之间的服务协议。SLA plugin可以为单个作业/整个集群接收或者发送SLA参数
Tdm
Tdm的全称是Time Division Multiplexing。在一些场景中,一些节点既属于Kubernetes集群也属于Yarn集群。Tdm plugin 需要管理员为这些节点标记为revocable node。Tdm plugin会在该类节点可被撤销的时间段内尝试把preemptable task调度给revocable node,并在该时间段之外清除revocable node上的preemptable task。Tdm plugin提高了volcano在调度过程中节点资源的分时复用能力
Numa-aware
当节点运行多个cpu密集的pod。基于pod是否可以迁移cpu已经调度周期cpu资源状况,工作负载可以迁移到不同的cpu核心下。许多工作负载对cpu资源迁移并不敏感。然而,有一些cpu的缓存亲和度以及调度延迟显著影响性能的工作负载,kubelet允许可选的cpu编排策略(cpu management)来确定节点上cpu资源的绑定分配
CRD
volcano中有3个很重要的cr资源,queue、podgroup、 vcjob
queue
queue就是队列, 在多租户场景下是个很重要的对象
上一个最简单地例子:
1 | apiVersion: scheduling.volcano.sh/v1beta1 |
- reclaimable: 表示该queue在资源使用量超过该queue所应得的资源份额时,是否允许其他queue回收该queue使用超额的资源,默认值为true
- weight: 为 (weight/total-weight) * total-resource(集群中所有资源的总和), weight是一个软约束
- capability(可选): 表示该queue内所有podgroup使用资源量之和的上限,它是一个硬约束
注意: queue capability需要与proportion插件一起使用,要不然不生效,即queue下的所有资源不可以超过capability总量
那queue的weight计算逻辑是怎样的呢?
根据queue的weight为queue分配集群资源的逻辑大致如下。
1 | # 每个queue deserved 初始为0 |
具体的计算方法将在volcano如何应对大规模任务系列之volcano源码解析一节中展开
podgroup
podgroup是一组强关联pod的集合, 例子如下:
1 | apiVersion: scheduling.volcano.sh/v1beta1 |
关键字段
- minMember
minMember表示该podgroup下最少需要运行的pod或任务数量。如果集群资源不满足miniMember数量任务的运行需求,调度器将不会调度任何一个该podgroup 内的任务。
- queue
queue表示该podgroup所属的queue。queue必须提前已创建且状态为open。
- priorityClassName
priorityClassName表示该podgroup的优先级,用于调度器为该queue中所有podgroup进行调度时进行排序。system-node-critical和system-cluster-critical 是2个预留的值,表示最高优先级。不特别指定时,默认使用default优先级或zero优先级。
- minResources
minResources表示运行该podgroup所需要的最少资源。当集群可分配资源不满足minResources时,调度器将不会调度任何一个该podgroup内的任务。
vcjob
Volcano Job,简称vcjob,是Volcano自定义的Job资源类型。区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器、支持最小运行pod数、 支持task、支持生命周期管理、支持指定队列、支持优先级调度等。Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景。
1 | apiVersion: batch.volcano.sh/v1alpha1 |
关键字段
- schedulerName
schedulerName表示该job的pod所使用的调度器,默认值为volcano,也可指定为default-scheduler。它也是tasks.template.spec.schedulerName的默认值。
- minAvailable
minAvailable表示运行该job所要运行的最少pod数量。只有当job中处于running状态的pod数量不小于minAvailable时,才认为该job运行正常。
- volumes
volumes表示该job的挂卷配置。volumes配置遵从kubernetes volumes配置要求。
- tasks.replicas
tasks.replicas表示某个task pod的副本数。
- tasks.template
tasks.template表示某个task pod的具体配置定义。
- tasks.policies
tasks.policies表示某个task的生命周期策略。
- policies
policies表示job中所有task的默认生命周期策略,在tasks.policies不配置时使用该策略。
- plugins
plugins表示该job在调度过程中使用的插件。
- queue
queue表示该job所属的队列。
- priorityClassName
priorityClassName表示该job优先级,在抢占调度和优先级排序中生效。
- maxRetry
maxRetry表示当该job可以进行的最大重启次数
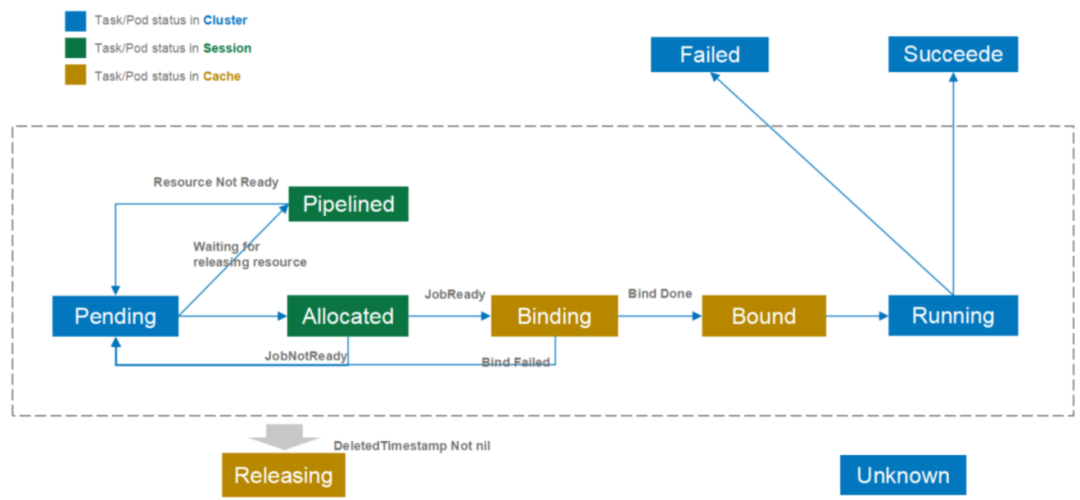
工作流
状态转换
这里列一下podgroup对象的状态转换, 只有理解了这个状态转换后才能对生产上出现的意料之外的问题进行快速排查,在后文中也会多次出现这个转换过程
本节大体介绍了volcano中比较重要的一些名词概念,volcano支持的东西比较多,所以不同的配置可能会产生截然不同的效果,接下来会结合生产情况来说明这些action/plugin是如何协调工作的以及在哪些场景下怎么配置效果最佳


